PinnedSukanya BaginPython in Plain EnglishOut of Bag (OOB) Evaluation in Random ForestsIntroduction4 min read·Oct 6, 2022--6--6
PinnedSukanya BagMy Experience Interviewing with Google!what I learned and what you can learn too..😮💨20 min read·Sep 9, 2022--16--16
PinnedSukanya BagA Comprehensive Guide to Time Series Analysis and ForecastingTime Series Analysis and Forecasting is a very pronounced and powerful study in data science, data analytics and Artificial Intelligence…19 min read·May 9, 2022--2--2
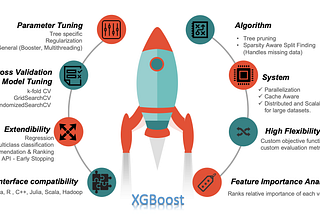
PinnedSukanya BaginPython in Plain EnglishThe Complete XGBoost Therapy with PythonDiscover XGBoost and get a deep understanding of this awesome algorithm, along with hands-on implementation.12 min read·Jan 5, 2022--4--4
Sukanya BagTop 15 Important Machine Learning Interview QuestionsAce your Data Science/ Machine Learning with these must know questions!18 min read·Nov 1, 2022----
Sukanya BagDemystifying DCNNs — the AlexNetwith hands-on implementation of AlexNet architecture7 min read·Oct 15, 2022----
Sukanya BagTop 15 Important Data Science Interview QuestionsIntroduction22 min read·Jun 28, 2022--1--1
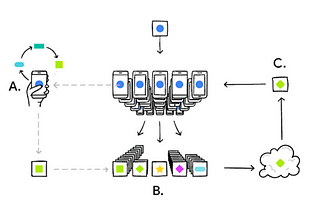
Sukanya BagFederated Learning — A Beginners GuideThis article was published as a part of the Data Science Blogathon at Analytics Vidhya.7 min read·May 15, 2021----
Sukanya BaginAnalytics VidhyaAutomated Hyperparameter Tuning with Keras Tuner and TensorFlow 2.0Building deep learning solutions in the real world is a process of constant experimentation and optimization.7 min read·May 12, 2021--1--1
Sukanya BaginAnalytics VidhyaText Summarization using BERT, GPT2, XLNetArtificial Intelligence has undoubtedly rationalized the extreme simulations of human intelligence in machines that are programmed to…8 min read·Apr 13, 2021--7--7